
行空板MultinomialNB模型实现古诗词作者快速识别
一、实践清单
硬件清单:

软件使用:Mind+编程软件x1
Mind+是一款拥有自主知识产权的国产青少年编程软件,集成各种主流主控板及上百种开源硬件,支持人工智能(AI)与物联网(IoT)功能,既可以拖动图形化积木编程,还可以使用Python/C/C++等高级编程语言,让大家轻松体验创造的乐趣。
二、实践过程
1、硬件搭建
1、将摄像头接入行空板的USB接口。
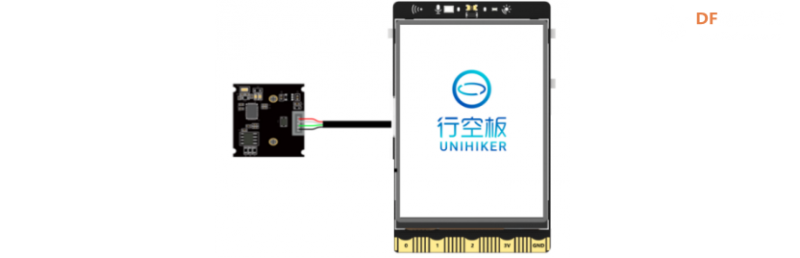
2、通过USB连接线将行空板连接到计算机。

2、软件编写
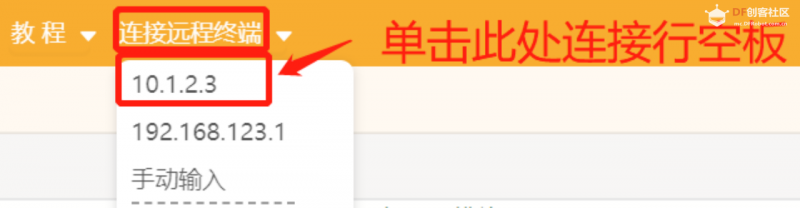
第一步:打开Mind+,远程连接行空板
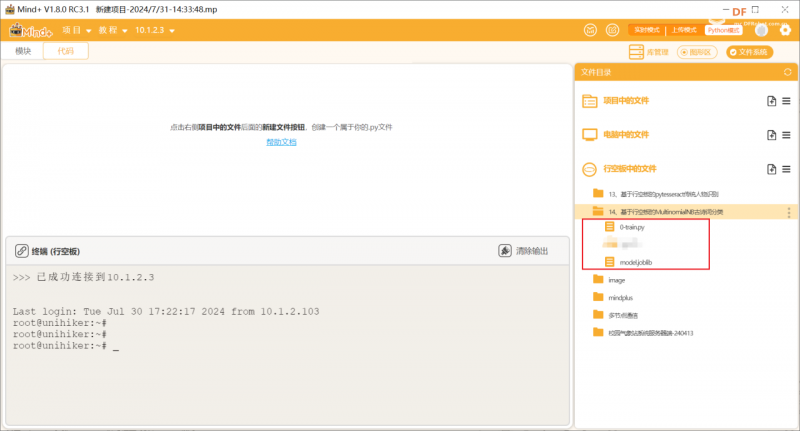
第二步:在“行空板的文件”中新建一个名为AI的文件夹,在其中再新建一个名为“基于行空板的MultinomialNB古诗词分类”的文件夹,导入本节课的依赖文件。Tips:0-train.py是用来训练古诗词和对应作者的程序,可以在其中增加数据集,model.joblib是训练生成的模型,用于对古诗词进行分类,这里我们直接用即可。
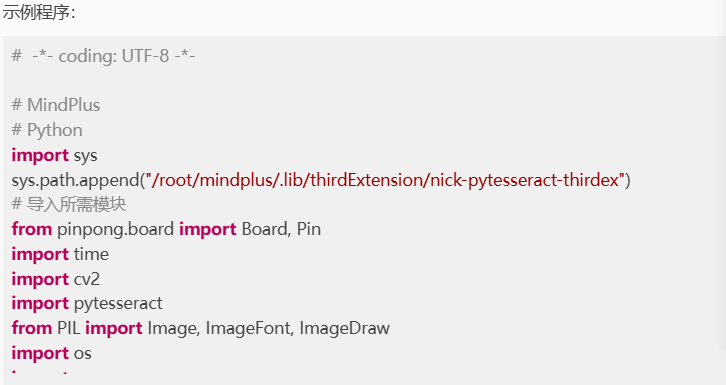
第三步:编写程序
在上述文件的同级目录下新建一个项目文件,并命名为“main.py”。
示例程序:
3、运行调试
第一步:运行主程序运行“main.py”程序,可以看到初始时屏幕上显示着摄像头拍摄到的实时画面,将摄像头画面对准古诗词,如这里为“红掌拨清波”,然后按下板载按键a,将此帧图像拍摄保存,之后自动识别图像上的文字,在Mind+软件终端,我们可以看到识别到的中文结果以及模型预测的该古诗词的作者。
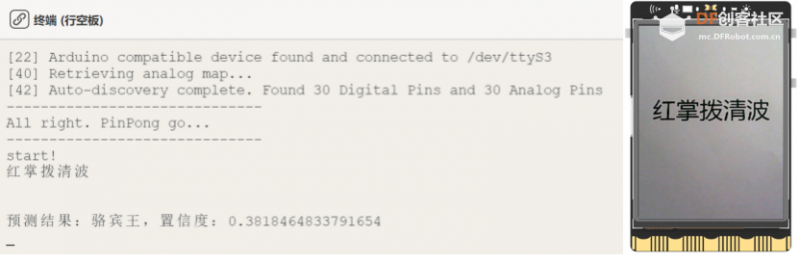
Tips:如果预测结果不准确,可以自行调整“0-train.py”中的数据集,训练模型。
4、程序解析
这段程序通过使用 OpenCV 库调用摄像头,实时从摄像头读取图像,然后使用 Tesseract 进行 OCR(光学字符识别)识别,并将结果显示在图像上。识别出的文本还会通过一个预训练的 MultinomialNB 模型进行分类,并显示预测结果和置信度。具体流程如下:
① 初始化:
· 导入所需的库和模块。
· 初始化 UNIHIKER 开发板。
· 设置 Tesseract OCR 的路径。
· 打开摄像头并设置分辨率和缓冲区大小。
· 创建一个全屏窗口用于显示图像。
② 定义函数:
· 定义 drawChinese 函数,用于在图像上绘制中文字符。
③ 加载模型:
· 使用 joblib 加载预训练的 MultinomialNB 模型。
④ 主循环:· 进入无限循环,从摄像头读取图像。
· 检测按键输入:· 如果按下 'b' 键,退出程序。
· 如果按下 'a' 键,捕获当前图像并保存到指定路径。
· 使用 Tesseract 进行 OCR 识别,提取图像中的文本。
· 使用预训练的 MultinomialNB 模型对提取的文本进行分类预测,输出预测结果和置信度。
· 在图像上绘制识别到的文本,并在窗口中显示处理后的图像。
⑤ 结束:
· 释放摄像头设备,并关闭所有 OpenCV 窗口。
三、知识园地
1. 了解MultinomialNB模型
MultinomialNB 是一个用于文本分类的机器学习模型,属于 scikit-learn 库中的一部分。它是多项式朴素贝叶斯(Multinomial Naive Bayes)分类器的实现。下面是对 MultinomialNB 的详细介绍:
概述
· 定义:MultinomialNB 是朴素贝叶斯分类器的一种,专门用于离散型特征(通常是单词计数或词频等文本数据)。
· 朴素贝叶斯模型:基于贝叶斯定理的一种简单但功能强大的概率分类器,假设特征之间是条件独立的。
· 多项式模型:适用于特征表示为多项式分布的场景,通常用于文本分类任务,如垃圾邮件检测和文档分类。
特点
· 简单有效:模型简单,计算效率高,适合大规模数据集。
· 文本分类:在自然语言处理(NLP)领域,尤其是文本分类任务中表现出色。
· 概率输出:可以输出每个类别的预测概率,帮助理解模型的信心度。
主要功能
1. 文本支持:
· 适合分类离散型特征,特别是词频或词袋模型(Bag-of-Words)表示的文本数据。
· 利用词频统计和类别条件概率进行分类预测。
2. 多类别支持:
· 支持多类别分类任务,可以处理多个类别的分类问题。
关于《行空板MultinomialNB模型实现古诗词作者快速识别》项目的详细信息,请访问DF创客社区,了解更多。
栏目相关